
Straylight Run
Software, Technology, PHP
 0
0
Ward Cunningham reflects on the history, motivation and common misunderstanding of the “debt metaphor” as motivation for refactoring.
The MySQL Query Cache is not very hard to understand. It is at its most basic a giant hash where the literal queries are the keys and the array of result records are the values. So this query:
SELECT event_name FROM events WHERE event_id = 8;
is different from this query:
SELECT event_name FROM events WHERE event_id = 10;
Important note! This means that even though your parameterized queries may look the same without the parameters, to the query cache, they are not!
As with all caches, the query cache is concerned about freshness of data. It takes perhaps the simplest approach possible to this problem by keeping track of any tables involved in your cached query. If any of these tables changes, it invalidates the query and removes it from the cache. This means that if your query returns frequently-changing data in its results, the query cache will invalidate the query frequently, leading to thrashing. For example, if you had a query that returned a view count of an event:
SELECT event_name, views FROM events WHERE event_id = 8;
Every time that event is viewed, the cached query will be invalidated. What’s the solution?
In general, write queries so that their result sets do not change often. In specific, mixing static attributes with frequently updated fields in a single table leads to thrashing, so separate out things like view counts and analytics into their own tables. The frequently updated data can be read with a separate query, or perhaps cached in your application in a data structure that periodically flushes to the DB.
This vertical partitioning of a single table’s columns into multiple tables helps immensely with the query cache. What’s more is that the table with the unchanging data can be further optimized for READS, and the frequently updated table can be optimized for UPDATES.
Here’s a good reason to keep all your development and production environments the same. The task was simple enough. I wanted to strip a UTF-8 encoded string of all punctuation. Here’s some example code that does it, using PHP’s PCRE library.
On PHP 5.2.4:
% php -i | grep PCRE
PCRE (Perl Compatible Regular Expressions) Support => enabled
PCRE Library Version => 6.6 06-Feb-2006
% php pcre_test.php
ss
On PHP 5.2.6:
% php -i | grep PCRE
PCRE (Perl Compatible Regular Expressions) Support => enabled
PCRE Library Version => 7.6 2008-01-28
% php pcre_test.php
TAGholy moley báts were killed by dogs for 50 ümlauts
Only took me a day to figure out.
Xdebug is an indispensable PHP tool. It is a PHP extension that adds a wealth of capabilities to your PHP development. There are so many features, I’ll dive right in.
var_dump() Replacement
Xdebug replaces PHP’s var_dump() function for displaying variables. Xdebug’s version includes different colors for different types and places limits on the amount of array elements/object properties, maximum depth and string lengths. There are a few other functions…
My favorite part about this: the output is already pre-formatted, so no more echoing <pre> before every var_dump().
Stack Traces For Free
When Xdebug is activated it will show a stack trace whenever PHP decides to show a notice, warning, error etc. The information that stack traces display, and the way how they are presented, can be configured to suit your needs.
Even if you have display_errors off and all errors are sent to a log, the log will still contain the stack traces of any errors.
Function Traces
Xdebug allows you to log all function calls, including parameters and return values to a file in different formats.
This is the ultimate debugging trace. It will create a file with every function, including third-party libraries and PHP internal functions, that was executed along with its arguments. It also displays the execution time the function was called at (where 0 is the start of the request), and the total amount of memory used at that point. What I like to do is insert xdebug_start_trace() in the bootstrap file at the start of the page request. I wrap a condition around it to enable it by giving a secret GET parameter on the query string.
if ($_GET['debugflag'])
{
xdebug_start_trace();
}
Profiling
Xdebug’s built-in profiler allows you to find bottlenecks in your script and visualize those with an external tool such as KCacheGrind or WinCacheGrind.
Xdebug, in conjunction with KCacheGrind, can generate a profile call graph which serves as the ultimate profiling report. First, generate a cachegrind file from Xdebug by appending XDEBUG_PROFILE as a GET pararmeter to the URL of the page you want to profile. After the page loads, you will find a cachegrind output file in the output directory (specified in xdebug.ini). Run KCacheGrind and open the output file. You can then generate a call graph which looks something like this:
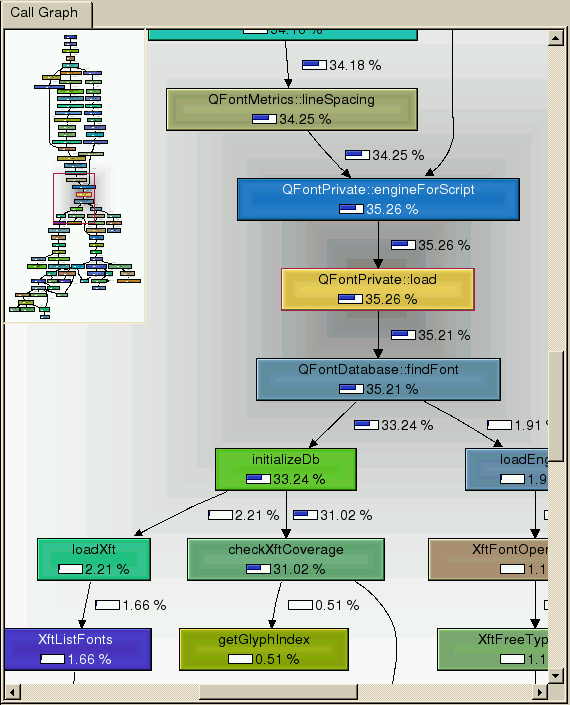
Limitations:
- KCacheGrind only runs on some kind of Unix. I attempted to run it on Windows/Cygwin unsuccessfully. There is a WinCacheGrind, but it does not offer the call graph feature.
- The call graph feature requires that the source code be local (this info is contained in the cachegrind file). Which means you have to run KCacheGrind on the server, or synchronize the code on the server locally.
In MySQL (and MySQL only AFAIK), INSERT has a clause called ON DUPLICATE KEY UDPATE. When ON DUPLICATE KEY UPDATE is used with INSERT, the insert will update the record if a value for a unique or primary key already exists, or else create a record if the value does not exist. So now when a form can either create a new something or edit an existing something, you can use one query to do it, and not have to query to see if the something exists already.
So instead of this:
$num = $db->getone("select count(*) from events where event_id = 15");
if ($num > 0)
{
$sql = "update events set name = 'New name' where event_id = 15";
}
else
{
$sql = "insert into events (event_id, name) values (null, 'New name')";
}
you can do something like this:
$id = (empty($_POST['id'])) ? null : $_POST['id'];
$sql = "insert into events (event_id, name) values ($id, 'New name') on duplicate key update name = 'New name'";
Neat, eh?
In case you’re wondering what the difference is between ON DUPLICATE KEY UPDATE and a REPLACE query, a REPLACE fires a DELETE followed by an INSERT query, as opposed to a real UPDATE.
 Back to top
Back to topAbout Me
 Gerard Sychay is a software developer in beautiful Cincinnati, OH, and partner at Differential. Nowadays, I do most of my blogging at the Differential blog.
Gerard Sychay is a software developer in beautiful Cincinnati, OH, and partner at Differential. Nowadays, I do most of my blogging at the Differential blog.


