
Straylight Run
Software, Technology, PHP
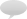 2
2
The typical argument for database abstraction is database portability. By abstracting the database, you are free to switch from one RDBMS to another effortlessly. Popular database abstraction layers are PEAR MDB2, ADOdb, and built-in PHP PDO library (not quite a database abstraction layer, but we’ll throw it in there anyway).
But there are three problems with that logic.
- How often are you going to switch databases in the life of your application anyway? I don’t know if I’ve ever switched a database out from under an application. Ever.
- To achieve true database independence, you’ll need to avoid using all the little syntax nuances that vary from DB to DB (e.g. the MySQL LIMIT clause) and avoid any feature in that database that makes it interesting (e.g. say goodbye to ON DUPLICATE KEY UPDATE). Chances are, you haven’t done these things. So to switch databases, your biggest problem will not be having to change all the mysql_* calls to ora_* or whatever.
- As with any layer, when you add another layer, there will always be some performance impact.
In light of these reasons, database dependence can be a good thing. You can take advantage of features in the RDBMS. And if you can make native calls directly to the extension, you’re saving a lot of code from being executed.
But still, something feels wrong from having all those native function calls throughout the codebase. The solution is database access abstraction, which does not attempt to abstract away the entire database, but attempts to abstract away access to the database.
Practically, this means building a wrapper class around your database code. Then, your application can use this wrapper class for its database needs. This is somewhat the best of both worlds. If you do need to switch DB’s, all your native functions calls will at least be in one file. You can also insert any system-wide logic pertaining to DB’s in this one class. For example, if you move to a replicated MySQL environment, you’ll need to direct READ queries to connect to one of multiple slave servers, and direct WRITE queries to the master server. This seems like an obvious thing to do, but a lot of people assume using a DBAL is enough abstraction already.
At work, my biggest motivation was performance. Running tests on our current DBAL, ADOdb, against using the mysqli_* functions in PHP revealed significant performance gains in going without the DBAL, which makes sense.
This blog repeats much of the thinking here, but is a more comprehensive looks at the topic (though the language is confusing at times.)
I’ve mentioned Apache Bench before. Httperf serves the same purpose as ab, but has a few more features, and has one very nice value-add.
While ab cannot really simulate a user visiting a website and performing multiple requests, httperf can. You can feed it a number of URL’s to visit, and specify how many requests to send within one session. You can also spread out requests over a time period randomly according a uniform or Poisson distribution, or a constant.
But the big value-add is autobench. Autobench is a perl wrapper around httperf for automating the process of load testing a web server. Autobench runs httperf a specified number of times against a URI, increasing the number of requests per second (which I equate to -c in ab) so that the response rate or the response time can be graphed vs. requests per second. (So response rate or response time on the vertical, and requests per second on the horizontal.)
With this, you can generate pretty graphs like this:
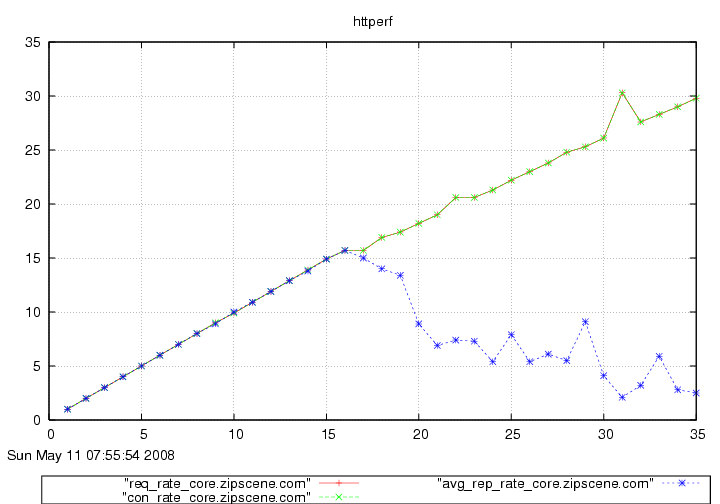
From the graphs above, you could determine the approximate capacity of your website. In the first graph, the number of responses received was equal to the number of requests sent until 16 req/sec. At 16 req/sec., the number of responses starts going down as requests begin to error out. In the second graph, the response time stays level at about 500ms (a reflection of your code and database) until 15 req/sec. At 16 req/sec. the time goes up to nearly 1s, and at 17 req/sec. the response time is over a second. You would conclude that the capacity of this website is around 15 requests per second.
The people who provide autobench also offer an excellent HOWTO on benchmarking web servers in general.
Apache Bench is either the first or second most useful PHP tool (with Xdebug being the other). I described the basic theory of Apache Bench in an earlier post. That’s a short post, so I won’t repeat it. This will be another short post, with a small note on how I use it day-to-day. If you are changing something in the system, a piece of code, a database setting, an OS setting… anything! for performance reasons, and you want to see if it makes any difference, use Apache Bench. Fire up a quick test before the change, and after the change. ab runs very quickly (on the order of a few minutes on a slow machine), so you can run 1000 requests and not have to worry about your sample size. I even run it on my laptop. Even though my laptop introduces a lot of noise, it still gives relative results. I usually run it two ways before the change, and two ways after.
% ab -n 1000 -c 1 http://www.whatever.com
That usually gets me a good idea of improving performance.
% ab -c 100 -t 60 http://www.whatever.com
That usually gets me a good idea of scaling under load.
UPDATE: There have been reports that Apache Bench is not reliable.
 Back to top
Back to topAbout Me
 Gerard Sychay is a software developer in beautiful Cincinnati, OH, and partner at Differential. Nowadays, I do most of my blogging at the Differential blog.
Gerard Sychay is a software developer in beautiful Cincinnati, OH, and partner at Differential. Nowadays, I do most of my blogging at the Differential blog.


