
Straylight Run
Software, Technology, PHP
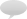 0
0
Since I knew that the MySQL Query Cache used the literal queries as keys, it made sense that MySQL did not cache queries with certain SQL functions in them, such as this one:
$sql = "select event_id from events where event_dt >= curdate()";
Because MySQL knows that this query run today is not the same query when it is run tomorrow. There are other SQL functions such as rand() and unix_timestamp() that will bypass the query cache. These are listed here.
So I avoid these functions when possible by calculating the value in PHP. For example, I’d rewrite the above query as:
$date = date('Y-m-d');
$sql = "select event_id from events where event_dt >= '$date'";
At work, every project has an .htaccess file containing at the least some mod_rewrite rules. This way, all I need to do to run a project is check it out of version control. I don’t need to modify my local Apache configuration.
But turning this option on and allowing .htaccess files may be a performance hit. More specifically, enabling the AllowOverride option in Apache is a performance hit. The Apache docs sums up the problem best:
“Wherever in your URL-space you allow overrides (typically
.htaccessfiles) Apache will attempt to open.htaccessfor each filename component. For example,DocumentRoot /www/htdocsAllowOverride all and a request is made for the URI
/index.html. Then Apache will attempt to open/.htaccess,/www/.htaccess, and/www/htdocs/.htaccess.”
So I disabled all .htaccess files in production, and inserted each file’s individual mod_rewrite rules into the main Apache config file. After a quick Apache Bench run, one project looked around 3% faster. Note that there are a few other useful optimizations on that page.
I’ve mentioned Apache Bench before. Httperf serves the same purpose as ab, but has a few more features, and has one very nice value-add.
While ab cannot really simulate a user visiting a website and performing multiple requests, httperf can. You can feed it a number of URL’s to visit, and specify how many requests to send within one session. You can also spread out requests over a time period randomly according a uniform or Poisson distribution, or a constant.
But the big value-add is autobench. Autobench is a perl wrapper around httperf for automating the process of load testing a web server. Autobench runs httperf a specified number of times against a URI, increasing the number of requests per second (which I equate to -c in ab) so that the response rate or the response time can be graphed vs. requests per second. (So response rate or response time on the vertical, and requests per second on the horizontal.)
With this, you can generate pretty graphs like this:
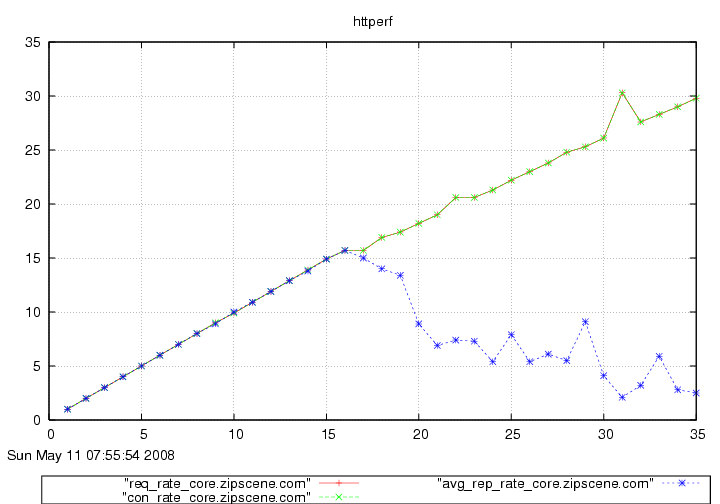
From the graphs above, you could determine the approximate capacity of your website. In the first graph, the number of responses received was equal to the number of requests sent until 16 req/sec. At 16 req/sec., the number of responses starts going down as requests begin to error out. In the second graph, the response time stays level at about 500ms (a reflection of your code and database) until 15 req/sec. At 16 req/sec. the time goes up to nearly 1s, and at 17 req/sec. the response time is over a second. You would conclude that the capacity of this website is around 15 requests per second.
The people who provide autobench also offer an excellent HOWTO on benchmarking web servers in general.
Apache Bench is either the first or second most useful PHP tool (with Xdebug being the other). I described the basic theory of Apache Bench in an earlier post. That’s a short post, so I won’t repeat it. This will be another short post, with a small note on how I use it day-to-day. If you are changing something in the system, a piece of code, a database setting, an OS setting… anything! for performance reasons, and you want to see if it makes any difference, use Apache Bench. Fire up a quick test before the change, and after the change. ab runs very quickly (on the order of a few minutes on a slow machine), so you can run 1000 requests and not have to worry about your sample size. I even run it on my laptop. Even though my laptop introduces a lot of noise, it still gives relative results. I usually run it two ways before the change, and two ways after.
% ab -n 1000 -c 1 http://www.whatever.com
That usually gets me a good idea of improving performance.
% ab -c 100 -t 60 http://www.whatever.com
That usually gets me a good idea of scaling under load.
UPDATE: There have been reports that Apache Bench is not reliable.
The MySQL Query Cache is not very hard to understand. It is at its most basic a giant hash where the literal queries are the keys and the array of result records are the values. So this query:
SELECT event_name FROM events WHERE event_id = 8;
is different from this query:
SELECT event_name FROM events WHERE event_id = 10;
Important note! This means that even though your parameterized queries may look the same without the parameters, to the query cache, they are not!
As with all caches, the query cache is concerned about freshness of data. It takes perhaps the simplest approach possible to this problem by keeping track of any tables involved in your cached query. If any of these tables changes, it invalidates the query and removes it from the cache. This means that if your query returns frequently-changing data in its results, the query cache will invalidate the query frequently, leading to thrashing. For example, if you had a query that returned a view count of an event:
SELECT event_name, views FROM events WHERE event_id = 8;
Every time that event is viewed, the cached query will be invalidated. What’s the solution?
In general, write queries so that their result sets do not change often. In specific, mixing static attributes with frequently updated fields in a single table leads to thrashing, so separate out things like view counts and analytics into their own tables. The frequently updated data can be read with a separate query, or perhaps cached in your application in a data structure that periodically flushes to the DB.
This vertical partitioning of a single table’s columns into multiple tables helps immensely with the query cache. What’s more is that the table with the unchanging data can be further optimized for READS, and the frequently updated table can be optimized for UPDATES.
 Back to top
Back to topAbout Me
 Gerard Sychay is a software developer in beautiful Cincinnati, OH, and partner at Differential. Nowadays, I do most of my blogging at the Differential blog.
Gerard Sychay is a software developer in beautiful Cincinnati, OH, and partner at Differential. Nowadays, I do most of my blogging at the Differential blog.


